-
Suggestion
-
Resolution: Unresolved
-
 P3: Somewhat important
P3: Somewhat important
-
None
-
None
-
None
Background
In general, the CI system is not executed for every commit, and probably never will due to limitations in hardware.
Thus, whenever the CI system is blocking due to a test failure, it generally reports a sequence of commits (the target sequence). The target sequence generally contains (except in certain cases of instability) the commit that is actually causing the blockage (the target commit).
Problem
The last step of pinpointing the target commit so that it can be fixed is currently a manual and often tedious task. Currently, all authors associated with the commit sequence are notified, even if only one of them needs to take action and fix the problem. This is error-prone for a number of reasons (an author might for example be reluctant to spend time investigating something that does not clearly appear to be his/her problem).
It would therefore be useful to automate the pinpointing step as well so that only the relevant author is notified. A notification would then effectively mean "this problem was introduced by a change that you submitted, and you are thus the main responsible for fixing it." (Someone else might end up doing the fix in practice, but that's beside the point.)
Failure in multiple tests
CI blockage may, in general, be caused by more than one test failure. This discussion makes the assumption that each test may be handled in isolation. It should be possible to locate the target commit independently for each failing test.
Basic case
The simplest scenario is the one where the test in question will be consistently passing during the first part of the target sequence and consistently failing during the last part:
pass pass pass pass FAIL FAIL FAIL FAIL FAIL FAIL FAIL FAIL FAIL FAIL FAIL FAIL
^
|
bug1 = target
A basic binary search algorithm can be applied to locate the first SHA-1 of the 'fail' sequence.
Testing a SHA-1 for pass/fail would involve checking out the SHA-1, rebuild, and then execute only the test in question.
Note that it would be a good idea to keep the binaries around for a while in case we need to execute another test for the same SHA-1 shortly, e.g. if more than one test was causing the CI blockage.
Multisegment case
A more general scenario is the one where the first failure is fixed, but then followed by a second failure:
pass pass pass pass FAIL FAIL FAIL FAIL FAIL FAIL pass pass pass FAIL FAIL FAIL
^ ^ ^
| | |
bug1 fix1 bug2 = target
The basic binary search will generally not give the correct answer in this case (particularly not in the case above, since the initial midpoint falls in the wrong segment of failures!).
Note that this is only a problem when using binary searching. A basic linear traversal from the last SHA-1 would have correctly found the target. Sacrificing speed for robustness like this is however not advisable for two reasons:
- The case is unlikely to occur very often.
- In the case is does happen, and the algorithm reports the wrong SHA-1, the worst that could happen is that someone fixes the first bug one more time (thus wasting time). It should then become apparent (when applying the fix after the latest SHA-1) that the second bug is not really fixed. At that point, the proper fix needs to be written, and that's it. Normally though, a manual comparison between the second (= current) test failure and the commit that introduced the first test failure ought to show some kind of mismatch and thus hinting at a case like this.
Unstable case
An unstable test is one that sometimes fails and sometimes passes depending on some external condition (such as time of day, state of the network, state of the window manager etc.).
The CI system currently works like this: Whenever a test fails, it is executed an additional time. If it fails twice, it is considered an overall failure, otherwise it is ignored (effectively considered an overall pass) due to being unstable.
In general an unstable test shows a non-deterministic behavior: The minimum number of reruns to prove instability is not known in advance. The current CI algorithm may therefore sometimes erroneously flag an unstable test as failing.
How does this affect the problem of pinpointing the target commit?
There are two cases to consider when CI blockage is caused by an unstable test:
- Case 1: None of the commits in the target sequence introduces a fixable bug that affects this test. This means that the CI blockage must be false, i.e. the test would eventually have passed if re-executed many enough times. The basic binary search algorithm will pick an arbitrary SHA-1 in the target sequence (which one depends on the instability as such). Obviously, no SHA-1 in the target sequence will actually make sense. This leaves us with two possible options for unblocking CI:
- Option 1: Fix the instability itself.
- Option 2: Disable the test (if Option 1 is not possible) and create a JIRA task for it.
- Case 2: One of the commits in the target sequence does represent a fixable bug that affects this test so that it fails consistently from that point on.
If the basic binary search finds the target commit, we're done: The problem is fixed, and CI is hopefully unblocked. If not, it means that the instability still causes trouble, but then we're in Case 1 and should act accordingly.
If the target commit is not found (e.g. if the initial midpoint is a false failure occurring before the target commit), then it will appear like we're in Case 1 (although we're not), and we will try to solve the problem based on that assumption. Fixing only the instability itself will not help in this case, however, since the real bug still causes the test to fail. It's therefore likely that the test will just be disabled (Option 2 of Case 1).
Disabling the test for the wrong reason like this is unfortunate - especially since a real bug in the product might slip through (a real bug in the test itself would be less worrying). On the other hand, disabling the test should (regardless of the underlying reason) be accompanied by a JIRA task and followed up.
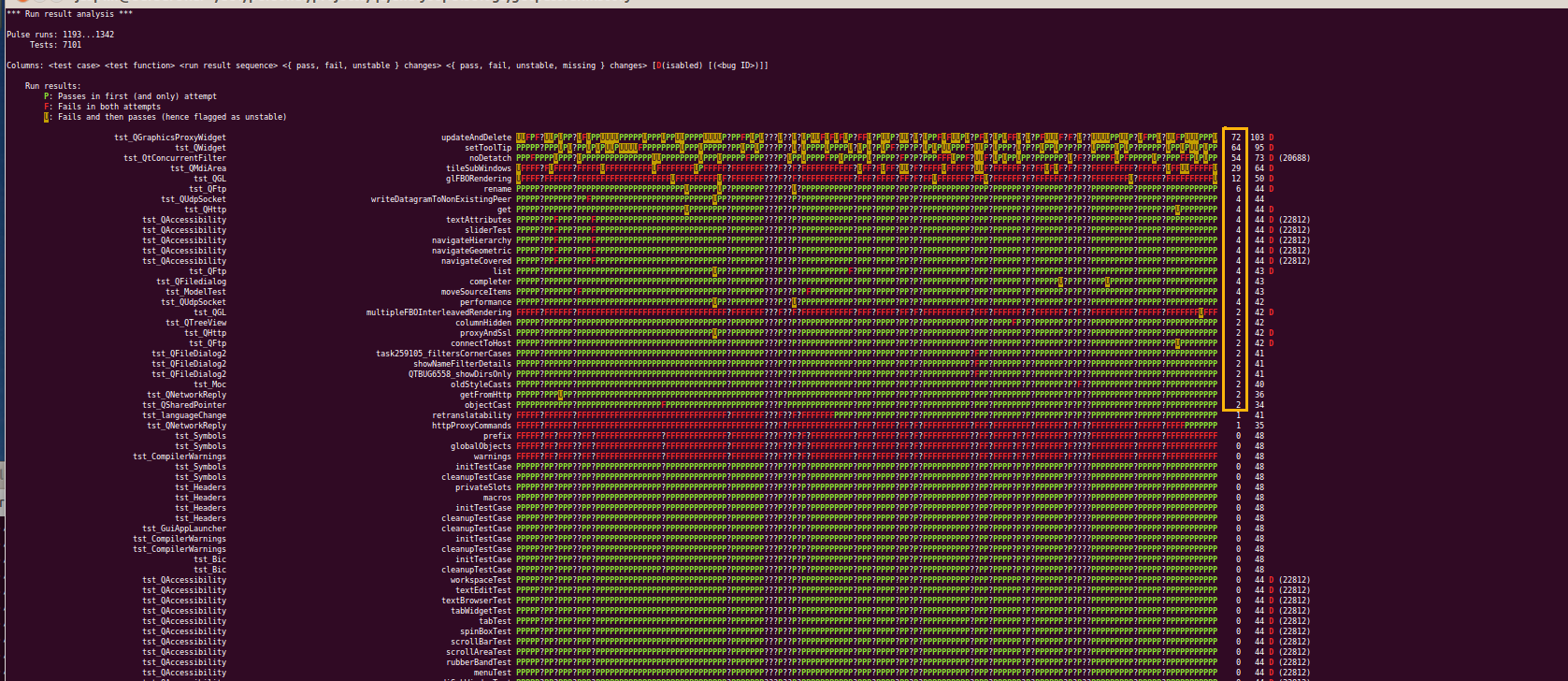
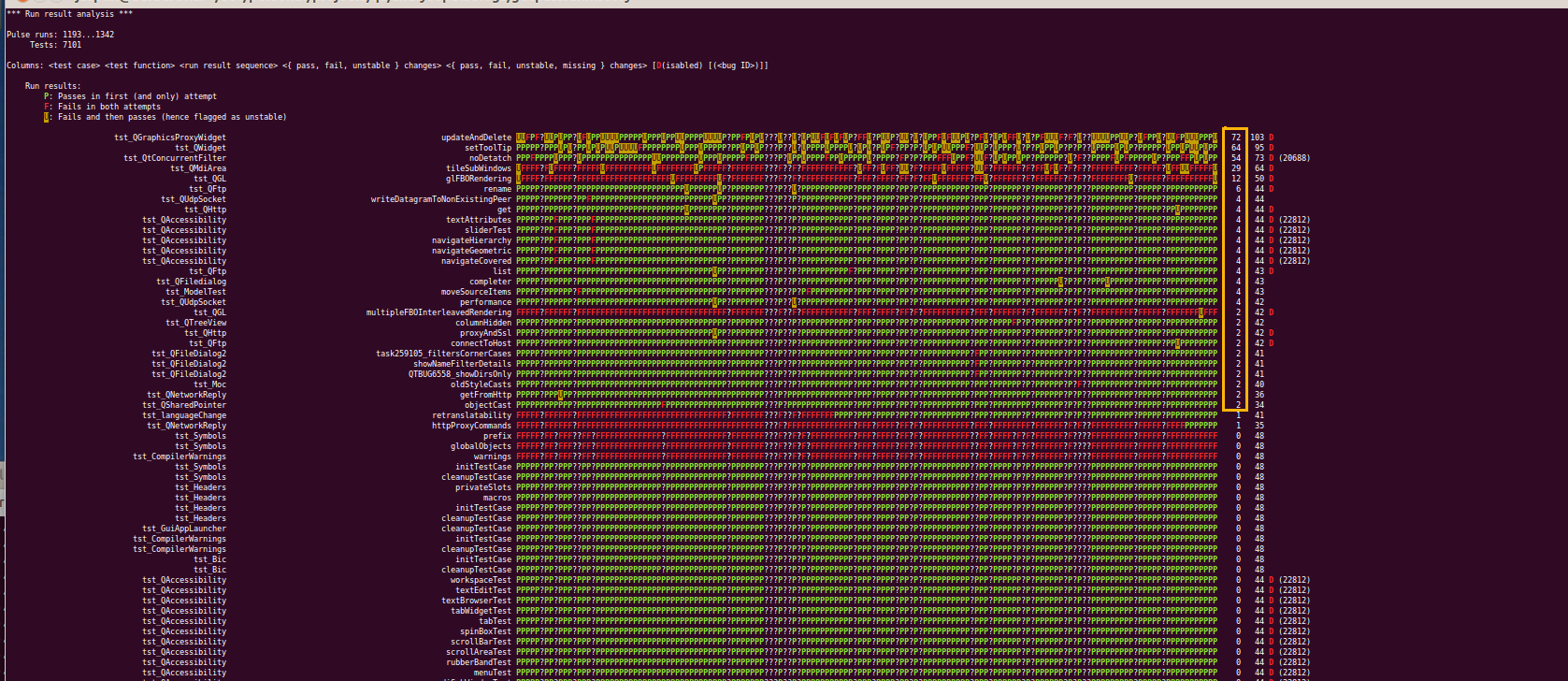
Instability statistics for QtBase
An analysis of the 150 most recent (as of 20/12 2011) pulse logs for QtBase on the Linux platform (release version) shows that less than 30 of a total of 7101 tests (test case / test function combinations) were unstable. And only 5 of them were really problematic. Most were already disabled in the CI system.
The screen shot below shows the output of the analysis. The unstable tests are indicated by a rectangle around the
{ PASS, FAIL, UNSTABLE }result changes during this run range for the unstable tests (the table is sorted by this number).
Conclusion
It seems worthwhile to apply a basic binary search algorithm for pinpointing the target commit.
Only the author of the target commit needs to be notified about the incident. (A copy should typically be sent to QA/admin people as well.)
The occasional "missed real bug due to unstable test" seems to be a small price to pay to avoid excessive notification. Such a situation should normally be caught (and documented) during a manual verification step anyway.
The report should also include the complete target sequence. This would provide a good basis for a manual investigation in case of problems due to the test being unstable.
- relates to
-
-
- Reported
-