-
Bug
-
Resolution: Won't Do
-
 P1: Critical
P1: Critical
-
None
-
5.9, 5.14.0
-
None
-
angle d3d11, Intel(R) UHD Graphics 630
-
All
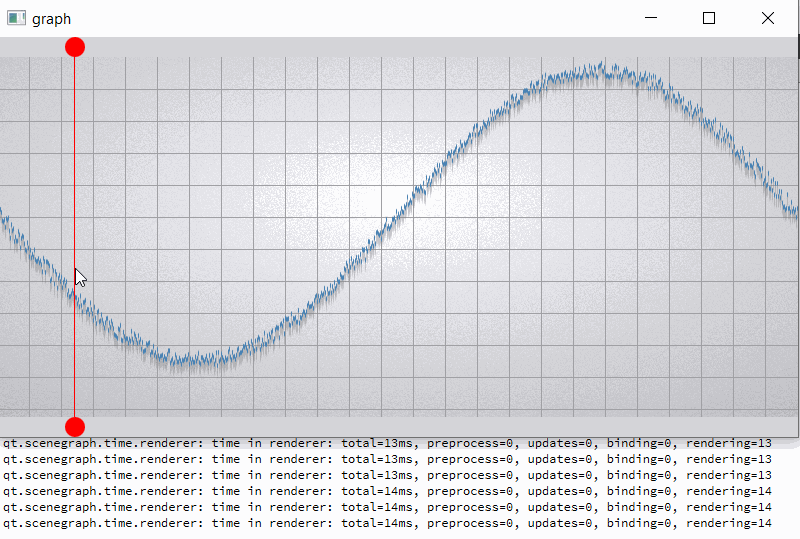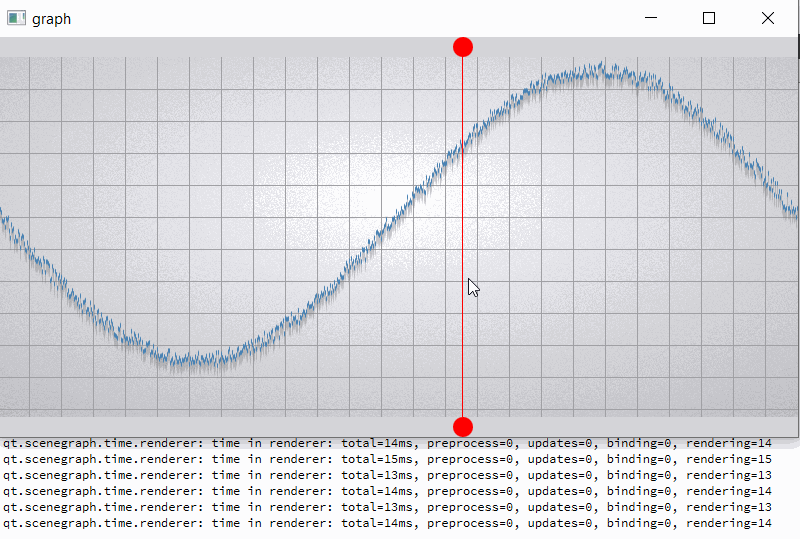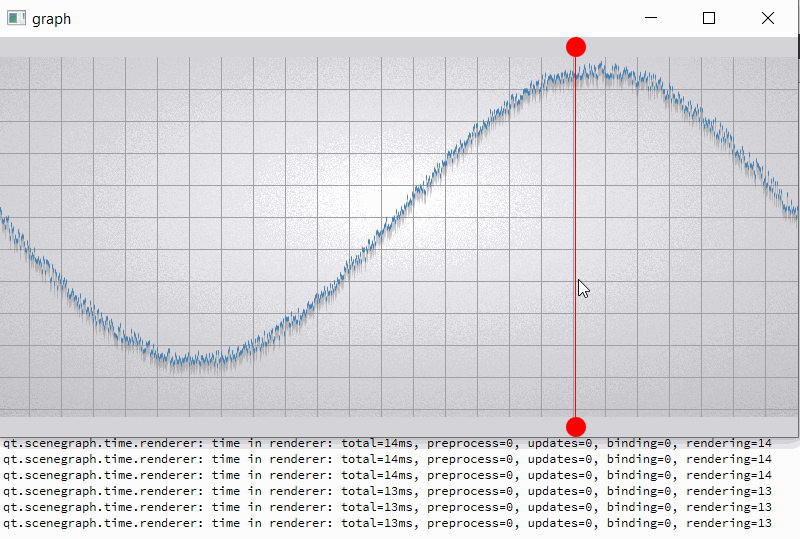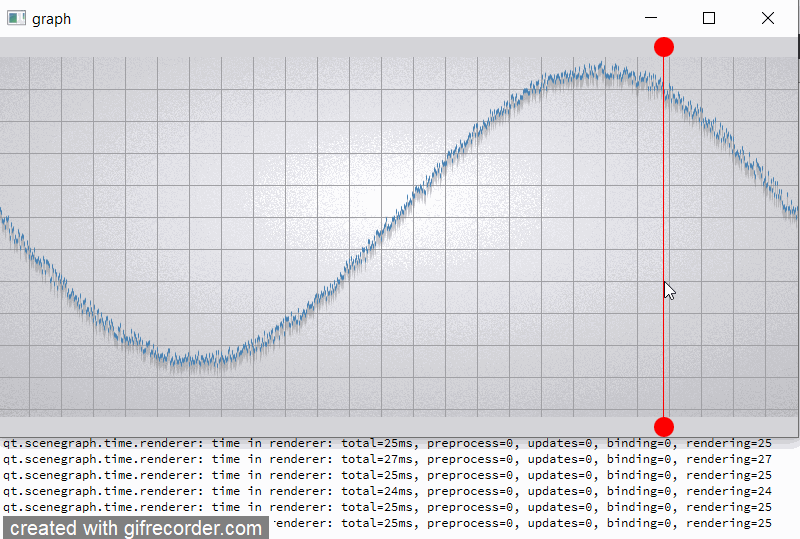
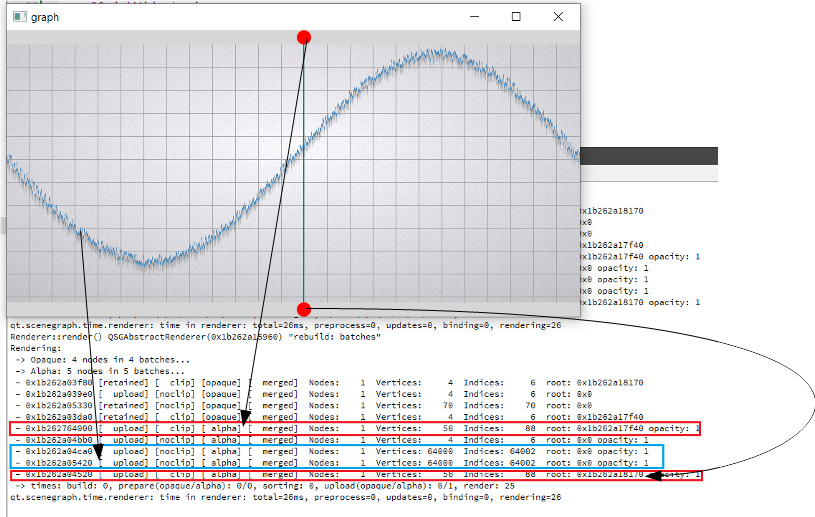
The current implementation of batch renderer reduce benefits of the GPU acceleration when working with alpha blended batches. Changes in batches with different render orders lead to the invalidation of batches located between them. But invalidation make a complete uploading of all data in these batch (see [Renderer::invalidateBatchAndOverlappingRenderOrders|https://code.qt.io/cgit/qt/qtdeclarative.git/tree/src/quick/scenegraph/coreapi/qsgbatchrenderer.cpp]). Thus, there is repeated data migration (CPU->GPU) of batches that have not even been changed.
Our company develops scientific software for the visualization of large amount of data: often geometry objects contain tens of thousands of vertices/indices and
have "big" per-vertex memory layout (for example about 50 bytes). And this described effect leads to a very cost rendering of frame (sometimes ~100 ms).
Such render behavior was introduced by commit...
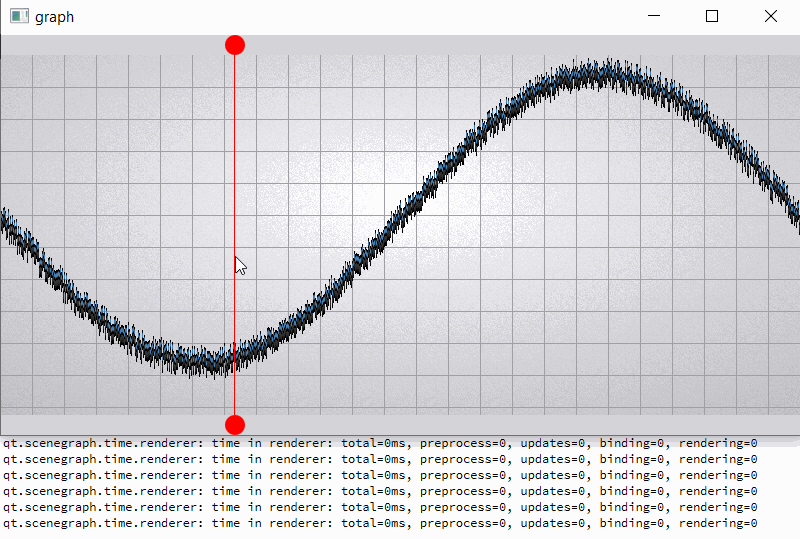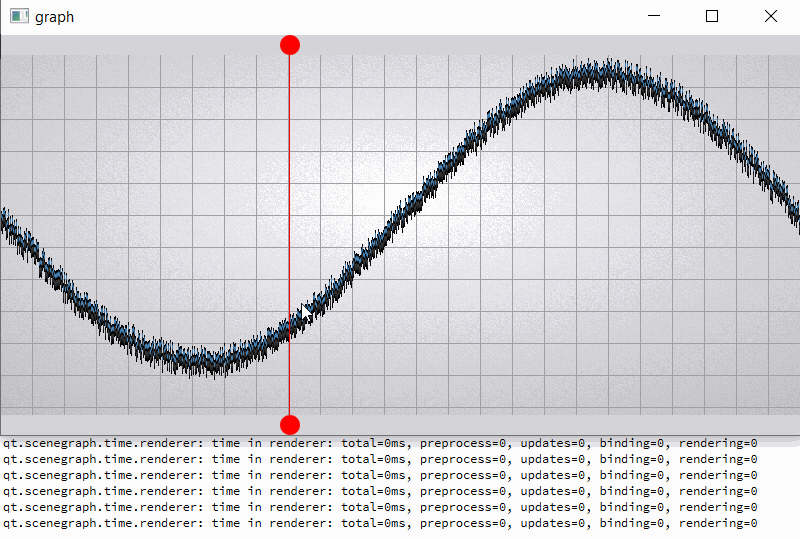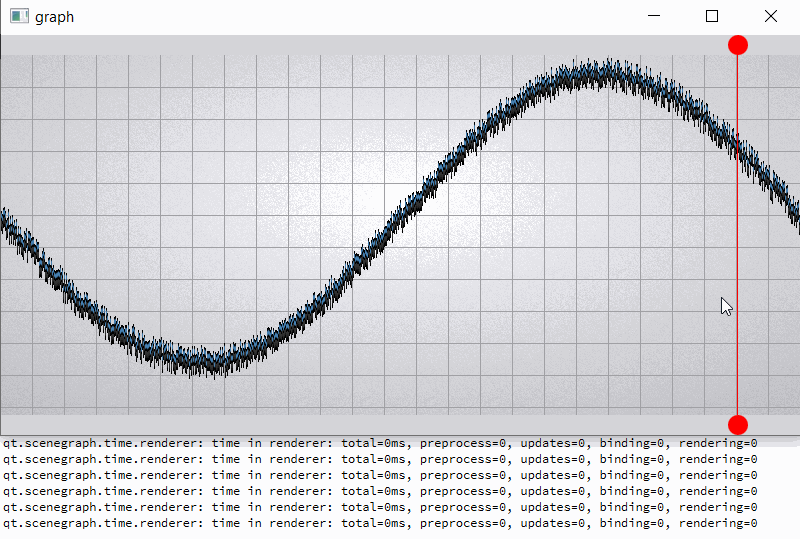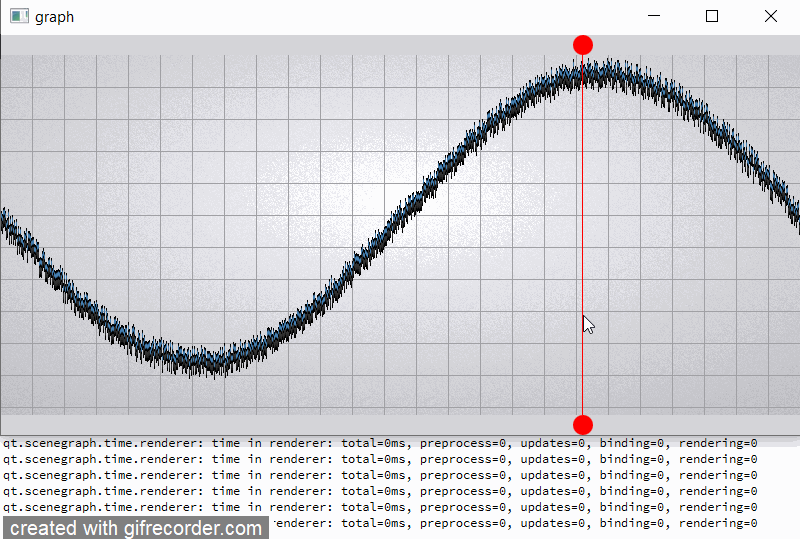
For clarity, I will give a slightly modified example "graph". In the example, I added two rounded red markers so that the render order of graph node is between them;
also increase the number of samples (32000) and per-vertex memory (~50 bytes) (see material_blending.gif and output.png).
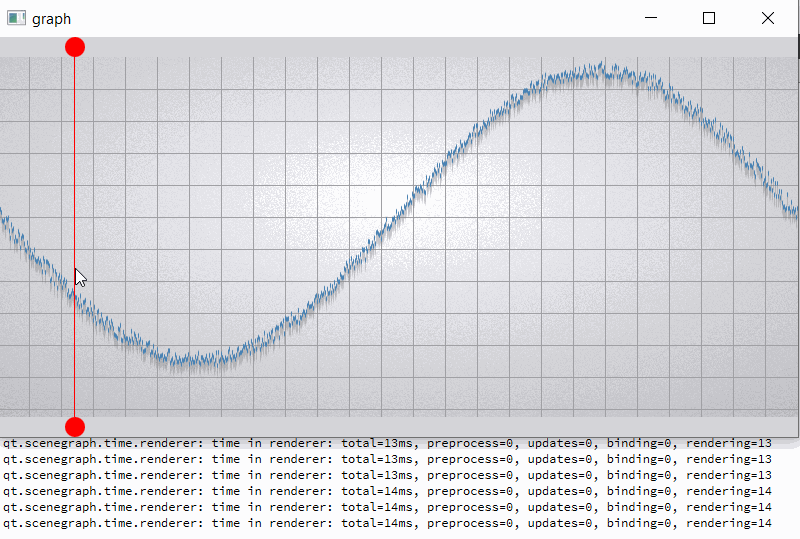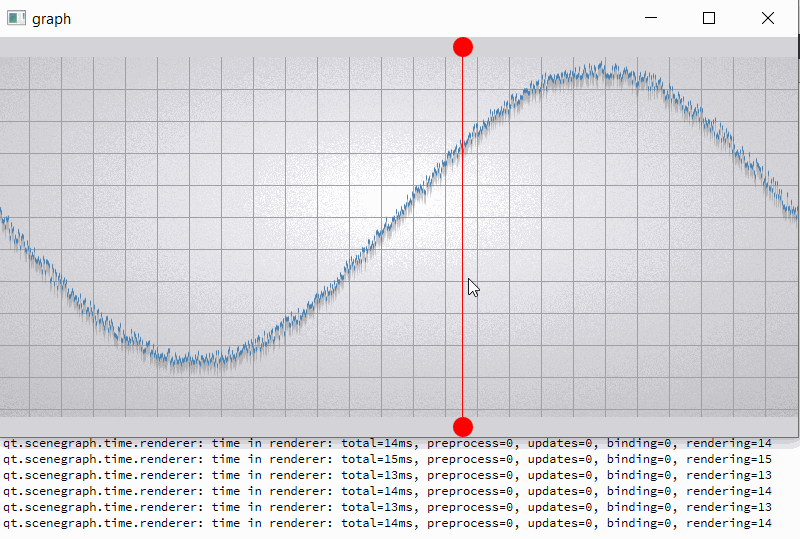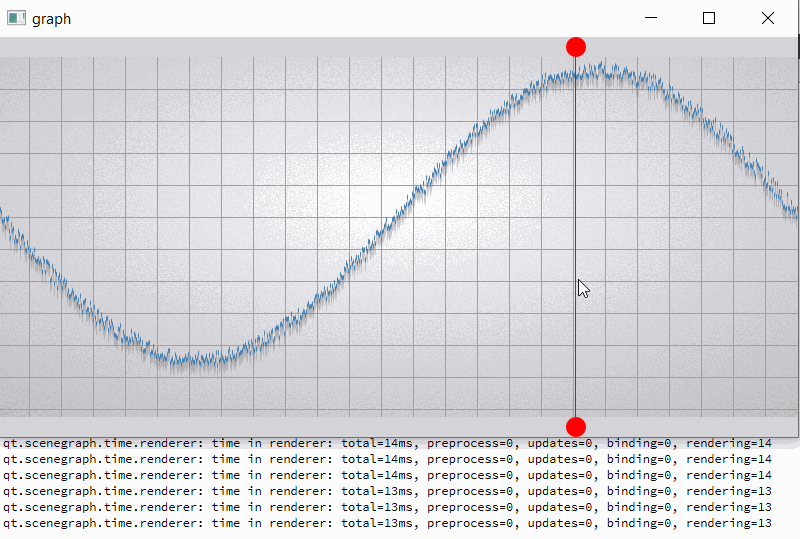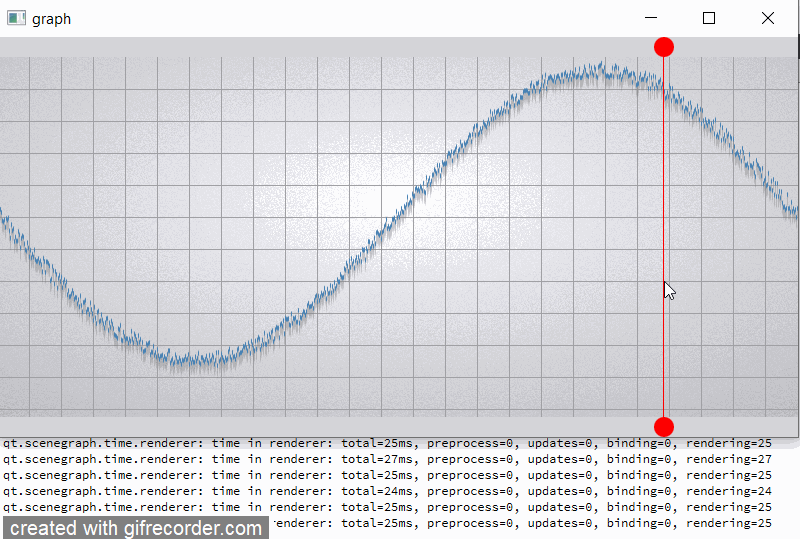
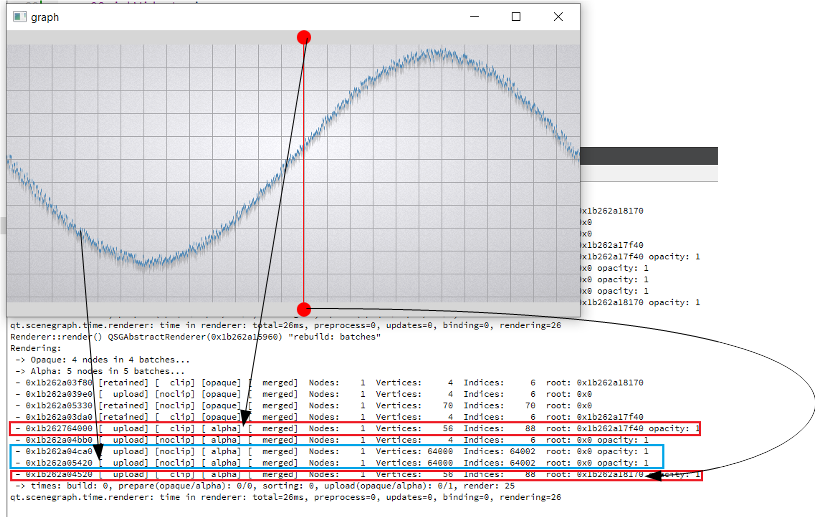
For comparison, I hacked a graph node for opaque batching by removing flag QSGMaterial::Blending -> opaque batch with graph node mark as "retained", etc. not uploading and have a lot of improvements (see material_opaque.gif).
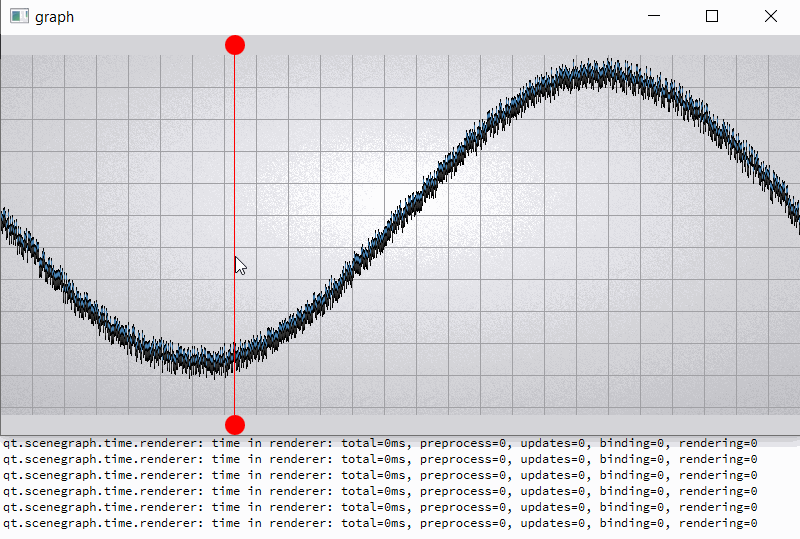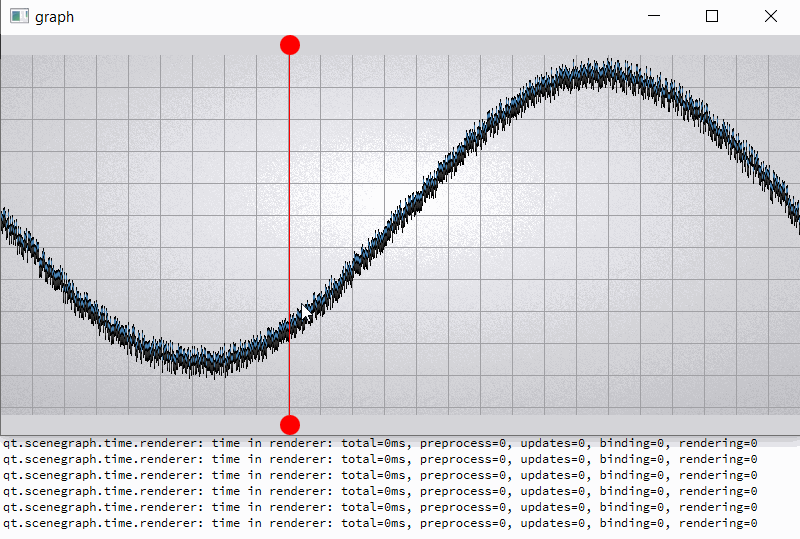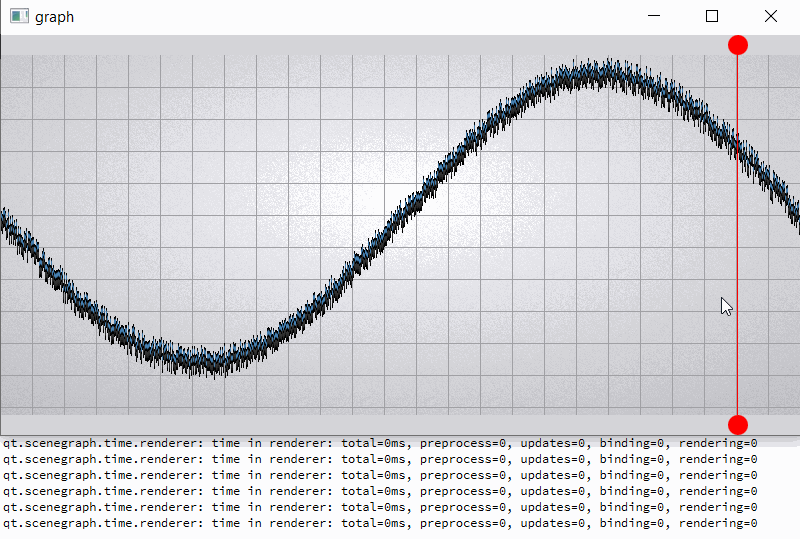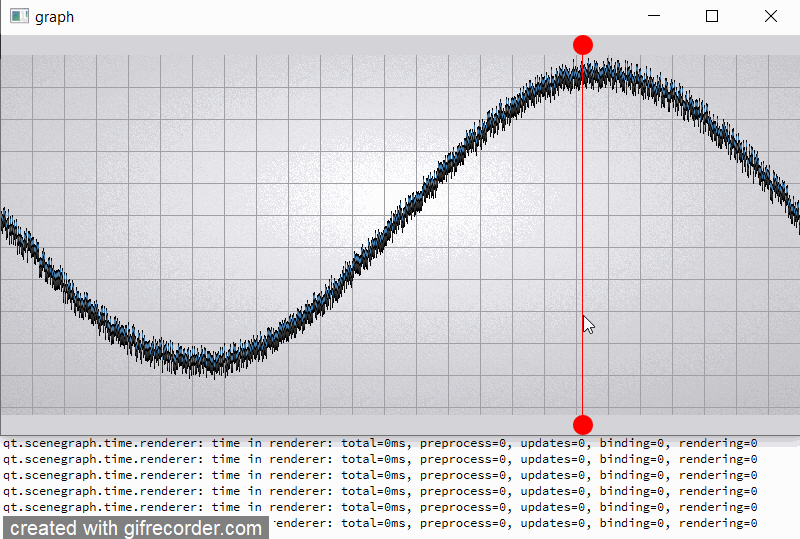
Of course, there is another approach to use QSGRenderNode, but it is lower level and requires more effort...